Describe how to work with relational data on Azure
- By Francesco Milano and Daniel A. Seara
- 5/30/2021
Relational data storage is described as storing information based on a predefined structure of the information. In this sample chapter from Exam Ref DP-900 Microsoft Azure Data Fundamentals, you will learn how to identify the right data offering for a relational workload, describe relational data structures, and more.
Relational data is the most used storage since the last quarter of the past century. It is likely the concept most students study at the very beginning of their careers. You will find concepts about how the data is stored, and the best ways to design them, in hundreds of books. No matter what kind of information you want to preserve, a relational database is most likely a good option.
Skills covered in this chapter:
Skill 2.1: Describe relational data workloads
Skill 2.2: Describe relational Azure data services
Skill 2.3: Identify basic management tasks for relational data
Skill 2.4: Describe query techniques for data using SQL language
Skill 2.1: Describe relational data workloads
Relational data storage is described as storing information based on a predefined structure of the information. Depending on the use of your data and your workload, you must select the technique that best matches your needs. Conceptually, in relational databases you try to define things to represent the entities in the real world, like persons, companies, products, bills, and so on. We use the term “relational” to describe the relation in the data representing an entity, and not just because, for example, one bill could be related to a person and a customer and was generated by a company. Moreover, it can have several products in the details, and all these elements are related. All this information must be stored in some way, and that is what we will cover here.
Identify the right data offering for a relational workload
If you analyze how your data has been managed in the past, usually you find one or more applications storing information in a centralized storage, probably a single database. Unless different business processes, or different areas, are involved with specific privacy or security reasons, you will find a lot of applications storing all the information in just one database. However, during recent years, this has been changing. A lot of information is now stored in several formats and places all around the world (in fact, all around the “cloud”).
And this is an important matter to consider. Not only must you manage the data, but you also must get information from several sources and, probably, adapt it to match the way your business uses the information.
Online transaction processing (OLTP)
This workload is what we typically get from business transactions, like bank transfers, online shopping, and cash machines, that are preserved in a data store. It is the repository for any transaction related to the activities.
In a health-care system, the information about every patient and each event—disease or symptom, treatment, blood analysis, X-ray, and so forth—consists of activities for the system, and usually they are related in order to manage the information clearly.
The concepts about OLTP are well known. The workload has been deeply analyzed, and many rules have been defined to make OLTP work better. Probably the most important is the atomicity, consistency, isolation, durability (ACID) concept, which defines the properties of database transactions that must be completed to guarantee sustainable operations.
Atomicity
The name “atomicity” derives from the concept of an atom. It is something that must be together. It is “all or nothing.”
Consider this scenario: A patient requires treatment in the ER. The doctor needs some laboratory checks for diagnostics purposes. The doctor performs some procedures to cure the diagnosed disease.
When the procedures are completed, several pieces of information must be recorded:
The patient’s symptoms
The list of laboratory checks
The result of those checks
Each procedure, medical instrument, medication and dosage
The closure: recommendations, future follow-up procedures, and so on
All this information and all the detailed costs of the procedures must be recorded as a single unit. It is not useful, for example, to have the symptoms without the laboratory results.
Ensuring that all the information is stored as one block, as an atom including all the parts at the same time, is atomicity.
Consistency
The information stored in a relational database usually has defined rules to ensure that all the information makes sense. Using the previous example, there is no sense in having the laboratory results without any indication of which patient they belong to, or the exact definition of the procedure.
Ensuring that the information can be related in a specific way in the future is consistency.
Isolation
Isolation ensures that other actors in the process do not access partial information.
Two different areas in the hospital using the same information must access the same data. If someone at the ER office is entering the information at the same time another person is preparing the bill, it will not be good if the second person obtains the already stored laboratory checks while the first person is still completing the registration of the procedures or drugs used to treat the patient.
During the update procedure, until the consistency has been maintained, the information for this specific transaction must be isolated from others.
Durability
Durability ensures that the information can be accessed later even after a system crash. Most relational database systems (RDBSs) use a mechanism to quickly store each step of an activity and then confirm all of them at the same time (known as a commit).
After the commit succeeds, the information is secure. Of course, IT departments must deal with external factors, but from a relational database point of view, the information is safe.
Online analytical processing (OLAP)
The OLAP workload, even when still a relational workload, was developed with data analysis in mind. You can think of it as looking to the past. The important element here is analyzing what happened instead of registering what is going on.
Using the previous example, OLAP will be used to evaluate how many patients the ER treated in the last week, or month, or year; how many require follow-up; the average number of laboratory procedures per patient; and so on.
The most important difference between OLTP and OLAP is that OLAP is implemented for reading big amounts of data for data analysis, whereas OLTP is designed for many parallel write transactions.
Another difference you can find in OLAP implementations is the fact that, usually, the OLAP data has been restructured to facilitate the queries.
Look at the partial entity-relationship diagram of products in the Adventure Works OLTP database, shown in Figure 2-1, and compare it with the diagram for products in the Adventure Works OLAP database, shown in Figure 2-2. The second one is more simplistic, but the tables contain more columns. Moreover, if you look at the Product table in the OLAP version, you will see that it has columns that are in other related tables in the OLTP model. That is because the OLAP data is flattened several times to accelerate the reads during the query process.
The OLAP database uses a semantic model instead of a database schema. The semantic model redefines the information from a business point of view, rather than using a structured point of view as the OLTP database schema does. This is because the business user, who is the final consumer for an OLAP implementation, knows the business entities but not the underlying data schema.
The semantic model usually contains calculations already performed, time-oriented calculations, aggregation from different tables to make it easier to read the information, and in some cases, aggregation from different sources.
)
FIGURE 2-1 OLTP database product relationships
)
FIGURE 2-2 OLAP database product relationship
When you define an OLAP workload, you must decide which kind of semantic model to use, as shown in Table 2-1.
Table 2-1 OLAP semantic models
OLAP Model |
Description |
Tabular |
Like OLTP models, this model uses concepts such as tables, columns, and relationships. |
Multidimensional |
A more traditional OLAP approach is used, based on cubes, dimensions, and measures. |
Data warehousing
Using information from different sources, during a long period of time, implies keeping historical information in a secure, consistent way. Moreover, the storage solution must not burden the other workloads with the analytical process. This is where a data warehouse comes in.
A data warehouse is the place to store historical and current information, preprocessed in ways that facilitate the business analytical queries to get better results. In the implementation of a data warehouse, procedures are used to cleanse the data and make it consistent. Because the information can come from disparate sources, it must be preprocessed to facilitate better results from the business analytical queries.
Several different tools and procedures are available to keep the information up-to-date in a data warehouse, but all can be defined as a three-part process: extract the information from the sources; store the results in the data warehouse; and transform, process, and ensure data quality in some parts of the process.
Sometimes, you prefer to transform the data before storing it in the data warehouse (the extract, transform, and load [ETL] process). In other circumstances, it could be more reliable, more secure, or simply cheaper to move all the information into the data warehouse and then process it (the extract, load, and transform [ELT] process).
Describe relational data structures
Relational data is about having the information stored according to specific structures and predefined elements. This ensures the quality of the queries, the relationships, and the consistency of the information. The following are several concepts related to how the information is structured in relational data structures.
Tables
A table is the basic structure where data is stored. A table predefines the parts of the data, and the information stored in it must match the defined schema.
A table defines columns to identify each piece of information about the entity it stores. Consider the set of information in Table 2-2 (let’s say it is information about sales regions).
Table 2-2 Table data sample
Name |
Country |
Start |
SalesLastYear |
North |
US |
05/01/2010 |
$ 3,298,694.49 |
Central |
US |
06/01/2012 |
$ 3,205,014.08 |
South |
US |
03/01/2008 |
$ 5,366,575.71 |
Canada |
CA |
08/01/2010 |
$ 5,693,988.86 |
France |
FR |
09/01/2006 |
$ 2,396,539.76 |
Germany |
DE |
10/01/2012 |
$ 1,307,949.79 |
Australia |
AU |
11/01/2018 |
$ 2,278,548.98 |
To store the information, a relational database must have a table that defines the columns, including their properties. The column definition specifies not only the name of each column (which must be unique to the table), but also the type of information the column will contain in each entry.
In some cases, when the entities you want to store have different sizes, most database engines allow you to define a specific or a maximum size.
Also, you can apply other kinds of restrictions. In this example, just one column is allowed to have no value, since the first time a new entry is added, no value for that column is added (for example, a new region will not have sales from the previous year, since it is new). This concept is represented in Table 2-3.
Table 2-3 Data columns and constrains
Column name |
Type |
Size |
Allow empty |
Name |
Characters |
100 |
No |
Country |
Characters |
2 |
No |
Start |
Date |
|
No |
SalesLastYear |
Money |
|
Yes |
Each database engine has its own data type definitions. However, most of them define the same standards, often with different nomenclatures and some specific data types not shared with others. But the most important types are the same for all of them. Table 2-4 shows the various data types.
Table 2-4 Standard data types
Information Type |
Standard Data types |
|
Characters |
Size |
Data Types |
Fixed length |
char nchar (Unicode) |
|
Variable length |
varchar nvarchar (Unicode) |
|
Numbers |
Size |
Data Types |
Integer |
integer smallinteger biginteger tinyinteger |
|
Non-integer |
decimal numeric float real double money |
|
Other data |
Size |
Data Types |
Dates |
smallDateTime dateTime time timespan |
|
Logical |
bit |
|
Other |
binary image Etc. |
Indexes
When you have a lot of information stored in a table, finding a specific entry could be time consuming. Imagine yourself in a room with hundreds of thousands of folders of information, trying to find a specific entry. Without classifications, you are in for a lot of work to find the information you are searching for.
Now think about having each folder with hundreds of pages . . . you will have to lift each of the folders to see if it is the correct one. That can be heavy work!
Something similar occurs in the database engine.
Finding your folder will be so much easier if you have a collection of tabs, with the tabs ordered and just the most important information to identify each one of your folders. That way, you can quickly locate the folder you are looking for in all your libraries.
That is the concept behind indexes. Instead of you reading each entire row, one at a time, to find the entry you need, the system searches an index to get the exact location of the information in the table.
In Figure 2-3, you can see how the index search works.
){kind=link}
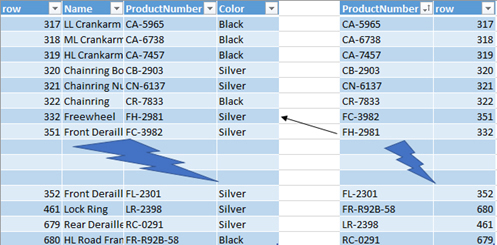
FIGURE 2-3 Index search
In a similar way, indexes can combine more than one column for lookup purposes.
Indexes can be used to:
Ensure uniqueness of each key in a table, defined as the unique key.
Establish the most important key to search, called the primary key.
Use relationships to speed up search correlation between data in columns in one table and the values of the column(s) of the primary key of another table.
Views
Once you have data stored in tables, you probably need to filter or regroup information in different ways for different users. Most important, it is often the case that not all the information stored in each table can be viewed by all your users. You might have sensitive information intended only for a subset of users or just a couple of columns some users need to view. In that case, you can use views to redefine the data to make it accessible in a reliable and secure form.
Consider a table with employee information. Any person in the company may need information from this table. However, salaries must not be visible to anyone except Human Resources personnel.
Here is another example. Suppose management needs the total sales by vendor, employee, year, and month. Instead of making management perform the calculation, you can have the information ready, in an already prepared view.
Keep in mind that the view does not store information. It is a virtual definition of how you want to see the information. Every time you query the view, the database platform will query the original table(s) to show you only the information you need.
A view is just a statement to query data from the table(s), not the final data. To enhance performance, when the database engine receives the order to store a view, it performs the following steps:
Checks the correctness of the statement itself
Verifies that all the columns and tables in use are present in the database
Determines the best plan to query the different parts of the data retrieved
Compiles the statement with that best plan (usually named the query or execution plan)
By doing this, the database engine, once executed the first time, will have the query plan in the cache and can use it.
Listing 2-1 is a sample of a view created to get information from five different tables.
Listing 2-1 View sample
CREATE VIEW [Salestotal]
AS
SELECT
YEAR([Soh].[Duedate]) AS [Year]
, MONTH([Soh].[Duedate]) AS [Month]
, [Prod].[Name] AS [Product]
, [Per].[Lastname] + ', ' + [Per].[Firstname] AS [Vendor]
, SUM([Sod].[Orderqty]) AS [Quantity]
, SUM([Sod].[Linetotal]) AS [Total]
FROM
[Sales].[Salesorderdetail] AS [Sod]
INNER JOIN
[Sales].[Salesorderheader] AS [Soh]
ON
[Sod].[Salesorderid]
= [Soh].[Salesorderid]
INNER JOIN
[Sales].[Salesperson] AS [Sp]
ON
[Soh].[Salespersonid]
= [Sp].[Businessentityid]
AND
[Soh].[Salespersonid]
= [Sp].[Businessentityid]
INNER JOIN
[Production].[Product] AS [Prod]
ON
[Sod].[Productid]
= [Prod].[Productid]
INNER JOIN
[Person].[Person] AS [Per]
ON
[Sp].[Businessentityid]
= [Per].[Businessentityid]
GROUP BY
YEAR([Soh].[Duedate])
, MONTH([Soh].[Duedate])
, [Prod].[Name]
, [Per].[Lastname] + ', ' + [Per].[Firstname];
Procedures
Procedures are another important element you can have in relational database engines. A procedure is a list of actions the database engine will execute, such as getting information, performing updates, or other tasks against the data.
Some procedures can act over several tables, making changes to them, calculating results, and updating the values in other tables. Each procedure implies at least a transaction (review the ACID concept).