Background to T-SQL querying and programming
- By Itzik Ben-Gan
- 10/7/2016
- Theoretical background
- SQL Server architecture
- Creating tables and defining data integrity
- Conclusion
SQL Server architecture
This section will introduce you to the SQL Server architecture, the different RDBMS flavors that Microsoft offers, the entities involved—SQL Server instances, databases, schemas, and database objects—and the purpose of each entity.
The ABCs of Microsoft RDBMS flavors
Initially, Microsoft offered mainly one enterprise-level RDBMS—an on-premises flavor called Microsoft SQL Server. These days, Microsoft offers an overwhelming plethora of options as part of its data platform, which constantly keeps evolving. Within its data platform, Microsoft offers three main RDBMS flavors, which you can think of as the ABC flavors: A for Appliance, B for Box (on-premises), and C for Cloud.
Box
The box, or on-premises RDBMS flavor, that Microsoft offers is called Microsoft SQL Server, or just SQL Server. This is the traditional flavor, usually installed on the customer’s premises. The customer is responsible for everything—getting the hardware, installing the software, patching, high availability and disaster recovery, security, and everything else.
The customer can install multiple instances of the product on the same server (more on this in the next section) and can write queries that interact with multiple databases. It is also possible to switch the connection between databases, unless one of them is a contained database (defined later).
The querying language used is T-SQL. You can run all the code samples and exercises in this book on an on-premises SQL Server implementation, if you want. See the Appendix for details about obtaining and installing an evaluation edition of SQL Server, as well as creating the sample database.
Appliance
The idea behind the appliance flavor is to provide the customer a complete turnkey solution with preconfigured hardware and software. Speed is achieved by things being co-located, with the storage being close to the processing. The appliance is hosted locally at the customer site. Microsoft partners with hardware vendors such as Dell and HP to provide the appliance offering. Experts from Microsoft and the hardware vendor handle the performance, security, and availability aspects for the customer.
There are several appliances available today, one of which is the Microsoft Analytics Platform System (APS), which focuses on data warehousing and big data technologies. This appliance includes a data-warehouse engine called Parallel Data Warehouse (PDW), which implements massively parallel processing (MPP) technology. It also includes HDInsight, which is Microsoft’s Hadoop distribution (big data solution). APS also includes a querying technology called PolyBase, which allows using T-SQL queries across relational data from PDW and nonrelational data from HDInsight.
Cloud
Cloud computing provides computing resources on demand from a shared pool of resources. Microsoft’s RDBMS technologies can be provided both as private-cloud and public-cloud services. A private cloud is cloud infrastructure that services a single organization and usually uses virtualization technology. It’s typically hosted locally at the customer site, and maintained by the IT group in the organization. It’s about self-service agility, allowing the users to deploy resources on demand. It provides standardization and usage metering. The database engine is usually a box engine (hence the same T-SQL is used to manage and manipulate the data).
As for the public cloud, the services are provided over the network and available to the public. Microsoft provides two forms of public RDBMS cloud services: infrastructure as a service (IaaS) and platform as a service (PaaS). With IaaS, you provision a virtual machine (VM) that resides in Microsoft’s cloud infrastructure. As a starting point, you can choose between several preconfigured VMs that already have a certain version and edition of SQL Server (box engine) installed on them. The hardware is maintained by Microsoft, but you’re responsible for maintaining and patching the software. It’s essentially like maintaining your own SQL Server installation—one that happens to reside on Microsoft’s hardware.
With PaaS, Microsoft provides the database cloud platform as a service. It’s hosted in Microsoft’s data centers. Hardware, software installation and maintenance, high availability and disaster recovery, and patching are all responsibilities of Microsoft. The customer is still responsible for index and query tuning, however.
Microsoft provides a number of PaaS database offerings. For OLTP systems, it offers the Azure SQL Database service. It’s also referred to more shortly as just SQL Database. The customer can have multiple databases on the cloud server (a conceptual server, of course) but cannot switch between databases.
Interestingly, Microsoft uses the same code base for SQL Database and SQL Server. So most of the T-SQL language surface is exposed (eventually) in both environments in the same manner. Therefore, most of the T-SQL you’ll learn about in this book is applicable to both environments. You can read about the differences that do exist here: https://azure.microsoft.com/en-us/documentation/articles/sql-database-transact-sql-information. You should also note that the update and deployment rate of new versions of SQL Database are faster than that of the on-premises SQL Server. Therefore, some T-SQL features might be exposed in SQL Database before they show up in the on-premises SQL Server version.
Microsoft also provides a PaaS offering for data-warehouse systems called Microsoft Azure SQL Data Warehouse (also called Azure SQL Data Warehouse or just SQL Data Warehouse). This service is basically PDW/APS in the cloud. Microsoft uses the same code base for both the appliance and the cloud service. You manage and manipulate data in APS and SQL Data Warehouse with T-SQL, although it’s not the same T-SQL surface as in SQL Server and SQL Database, yet.
Microsoft also offers other cloud data services, such as Data Lake for big data–related services, Azure DocumentDB for NoSQL document database services, and others.
Confused? If it’s any consolation, you’re not alone. Like I said, Microsoft provides an overwhelming plethora of database-related technologies. Curiously, the one thread that is common to many of them is T-SQL.
SQL Server instances
In the box product, an instance of SQL Server, as illustrated in Figure 1-5, is an installation of a SQL Server database engine or service. You can install multiple instances of on-premises SQL Server on the same computer. Each instance is completely independent of the others in terms of security and the data that it manages, and in all other respects. At the logical level, two different instances residing on the same computer have no more in common than two instances residing on two separate computers. Of course, same-computer instances do share the server’s physical resources, such as CPU, memory, and disk.
){kind=link}
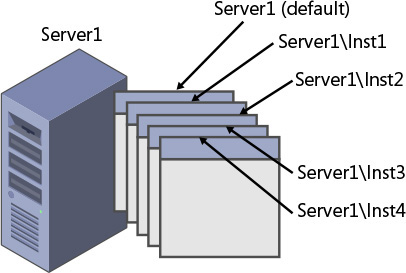
Figure 1-5 Multiple instances of SQL Server on the same computer.
You can set up one of the multiple instances on a computer as the default instance, whereas all others must be named instances. You determine whether an instance is the default or a named one upon installation; you cannot change that decision later. To connect to a default instance, a client application needs to specify the computer’s name or IP address. To connect to a named instance, the client needs to specify the computer’s name or IP address, followed by a backslash (\), followed by the instance name (as provided upon installation). For example, suppose you have two instances of SQL Server installed on a computer called Server1. One of these instances was installed as the default instance, and the other was installed as a named instance called Inst1. To connect to the default instance, you need to specify only Server1 as the server name. However, to connect to the named instance, you need to specify both the server and the instance name: Server1\Inst1.
There are various reasons why you might want to install multiple instances of SQL Server on the same computer, but I’ll mention only a couple here. One reason is to save on support costs. For example, to test the functionality of features in response to support calls or reproduce errors that users encounter in the production environment, the support department needs local installations of SQL Server that mimic the user’s production environment in terms of version, edition, and service pack of SQL Server. If an organization has multiple user environments, the support department needs multiple installations of SQL Server. Rather than having multiple computers, each hosting a different installation of SQL Server that must be supported separately, the support department can have one computer with multiple installed instances. Of course, you can achieve a similar result by using multiple virtual machines.
As another example, consider people like me who teach and lecture about SQL Server. For us, it is convenient to be able to install multiple instances of SQL Server on the same laptop. This way, we can perform demonstrations against different versions of the product, showing differences in behavior between versions, and so on.
As a final example, providers of database services sometimes need to guarantee their customers complete security separation of their data from other customers’ data. At least in the past, the database provider could have a very powerful data center hosting multiple instances of SQL Server, rather than needing to maintain multiple less-powerful computers, each hosting a different instance. More recently, cloud solutions and advanced virtualization technologies make it possible to achieve similar goals.
Databases
You can think of a database as a container of objects such as tables, views, stored procedures, and other objects. Each instance of SQL Server can contain multiple databases, as illustrated in Figure 1-6. When you install an on-premises flavor of SQL Server, the setup program creates several system databases that hold system data and serve internal purposes. After the installation of SQL Server, you can create your own user databases that will hold application data.
){kind=link}
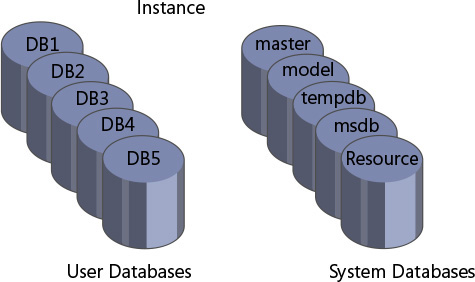
Figure 1-6 An example of multiple databases on a SQL Server instance.
The system databases that the setup program creates include master, Resource, model, tempdb, and msdb. A description of each follows:
master The master database holds instance-wide metadata information, the server configuration, information about all databases in the instance, and initialization information.
Resource The Resource database is a hidden, read-only database that holds the definitions of all system objects. When you query system objects in a database, they appear to reside in the sys schema of the local database, but in actuality their definitions reside in the Resource database.
model The model database is used as a template for new databases. Every new database you create is initially created as a copy of model. So if you want certain objects (such as data types) to appear in all new databases you create, or certain database properties to be configured in a certain way in all new databases, you need to create those objects and configure those properties in the model database. Note that changes you apply to the model database will not affect existing databases—only new databases you create in the future.
tempdb The tempdb database is where SQL Server stores temporary data such as work tables, sort and hash table data, row versioning information, and so on. With SQL Server, you can create temporary tables for your own use, and the physical location of those temporary tables is tempdb. Note that this database is destroyed and re-created as a copy of the model database every time you restart the instance of SQL Server.
msdb The msdb database is used mainly by a service called SQL Server Agent to store its data. SQL Server Agent is in charge of automation, which includes entities such as jobs, schedules, and alerts. SQL Server Agent is also the service in charge of replication. The msdb database also holds information related to other SQL Server features, such as Database Mail, Service Broker, backups, and more.
In an on-premises installation of SQL Server, you can connect directly to the system databases master, model, tempdb, and msdb. In SQL Database, you can connect directly only to the system database master. If you create temporary tables or declare table variables (more on this topic in Chapter 11, “Programmable objects”), they are created in tempdb, but you cannot connect directly to tempdb and explicitly create user objects there.
You can create multiple user databases (up to 32,767) within an instance. A user database holds objects and data for an application.
You can define a property called collation at the database level that will determine default language support, case sensitivity, and sort order for character data in that database. If you do not specify a collation for the database when you create it, the new database will use the default collation of the instance (chosen upon installation).
To run T-SQL code against a database, a client application needs to connect to a SQL Server instance and be in the context of, or use, the relevant database. The application can still access objects from other databases by adding the database name as a prefix.
In terms of security, to be able to connect to a SQL Server instance, the database administrator (DBA) must create a login for you. The login can be tied to your Microsoft Windows credentials, in which case it is called a Windows authenticated login. With a Windows authenticated login, you can’t provide login and password information when connecting to SQL Server because you already provided those when you logged on to Windows. The login can be independent of your Windows credentials, in which case it’s called a SQL Server authenticated login. When connecting to SQL Server using a SQL Server authenticated login, you will need to provide both a login name and a password.
The DBA needs to map your login to a database user in each database you are supposed to have access to. The database user is the entity that is granted permissions to objects in the database.
SQL Server supports a feature called contained databases that breaks the connection between a database user and an instance-level login. The user (Windows or SQL authenticated) is fully contained within the specific database and is not tied to a login at the instance level. When connecting to SQL Server, the user needs to specify the database he or she is connecting to, and the user cannot subsequently switch to other user databases.
So far, I’ve mainly mentioned the logical aspects of databases. If you’re using SQL Database, your only concern is that logical layer. You do not deal with the physical layout of the database data and log files, tempdb, and so on. But if you’re using a box version of SQL Server, you are responsible for the physical layer as well. Figure 1-7 shows a diagram of the physical database layout.
)
Figure 1-7 Database layout.
The database is made up of data files, transaction log files, and optionally checkpoint files holding memory-optimized data (part of a feature called In-Memory OLTP, which I describe shortly). When you create a database, you can define various properties for data and log files, including the file name, location, initial size, maximum size, and an autogrowth increment. Each database must have at least one data file and at least one log file (the default in SQL Server). The data files hold object data, and the log files hold information that SQL Server needs to maintain transactions.
Although SQL Server can write to multiple data files in parallel, it can write to only one log file at a time, in a sequential manner. Therefore, unlike with data files, having multiple log files does not result in a performance benefit. You might need to add log files if the disk drive where the log resides runs out of space.
Data files are organized in logical groups called filegroups. A filegroup is the target for creating an object, such as a table or an index. The object data will be spread across the files that belong to the target filegroup. Filegroups are your way of controlling the physical locations of your objects. A database must have at least one filegroup called PRIMARY, and it can optionally have other user filegroups as well. The PRIMARY filegroup contains the primary data file (which has an .mdf extension) for the database, and the database’s system catalog. You can optionally add secondary data files (which have an .ndf extension) to PRIMARY. User filegroups contain only secondary data files. You can decide which filegroup is marked as the default filegroup. Objects are created in the default filegroup when the object creation statement does not explicitly specify a different target filegroup.
The SQL Server database engine includes a memory-optimized engine called In-Memory OLTP. You can use this feature to integrate memory-optimized objects, such as memory-optimized tables and natively compiled procedures, into your database. To do so, you need to create a filegroup in the database marked as containing memory-optimized data and, within it, at least one path to a folder. SQL Server stores checkpoint files with memory-optimized data in that folder, and it uses those to recover the data every time SQL Server is restarted.
Schemas and objects
When I said earlier that a database is a container of objects, I simplified things a bit. As illustrated in Figure 1-8, a database contains schemas, and schemas contain objects. You can think of a schema as a container of objects, such as tables, views, stored procedures, and others.
){kind=link}
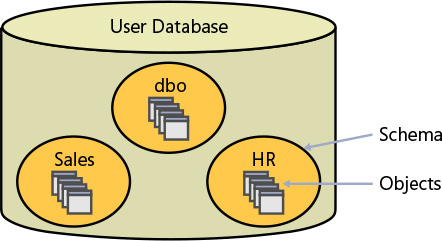
Figure 1-8 A database, schemas, and database objects.
You can control permissions at the schema level. For example, you can grant a user SELECT permissions on a schema, allowing the user to query data from all objects in that schema. So security is one of the considerations for determining how to arrange objects in schemas.
The schema is also a namespace—it is used as a prefix to the object name. For example, suppose you have a table named Orders in a schema named Sales. The schema-qualified object name (also known as the two-part object name) is Sales.Orders. You can refer to objects in other databases by adding the database name as a prefix (three-part object name), and to objects in other instances by adding the instance name as a prefix (four-part object name). If you omit the schema name when referring to an object, SQL Server will apply a process to resolve the schema name, such as checking whether the object exists in the user’s default schema and, if the object doesn’t exist, checking whether it exists in the dbo schema. Microsoft recommends that when you refer to objects in your code you always use the two-part object names. There are some relatively insignificant extra costs involved in resolving the schema name when you don’t specify it explicitly. But as insignificant as this extra cost might be, why pay it? Also, if multiple objects with the same name exist in different schemas, you might end up getting a different object than the one you wanted.