Design data storage solutions
- By Ashish Agrawal, Avinash Bhavsar, Gurvinder Singh, Mohammad Sabir Sopariwala
- 6/26/2023
- Skill 2.1: Design a data storage solution for relational data
- Skill 2.2: Design data integration
Skill 2.2: Design data integration
In the current information age, large amounts of data are generated by many applications, and the amount of data being generated is growing exponentially. An organization must collect data from multiple sources, such as business partners, suppliers, vendors, manufacturers, customers, social media, and so on. This exploding volume of data, disparate data sources, and cloud adoption are crucial factors for organizations that need to redesign or adopt a new data integration solution to meet business needs. In this skill, you look at various options available in the Microsoft Azure cloud platform for data integration and data analysis.
Recommend a solution for data integration
Microsoft’s Azure Data Factory is a solution for today’s data integration needs. Let’s look at Azure Data Factory and its capabilities.
Azure Data Factory (ADF) is a cloud-based, fully managed, serverless, and cost-effective data integration and data transformation service that allows you to create data-driven work-flows and to orchestrate, move, and transform data. It is designed for complex hybrid extract, transform, load (ETL) and extract, load, transform (ELT) patterns.
ADF does not store data; it ingests data from various sources, transforms it, and publishes it to data stores called sinks. You can also run SQL server integration services (SSIS) packages in Azure Data Factory, which provides assistance in migrating existing SSIS packages.
An Azure Data Factory pipeline can be created by using these tools or APIs:
Azure Portal
Visual Studio
PowerShell
.NET API
REST API
Azure Resource Manager template
Azure Data Factory supports the following file formats:
Avro
Binary
Common Data Model
Delimited text
Delta
Excel
JSON
ORC
Parquet
XML
Let’s look at the Azure Data Factory components before delving into how ADF works:
Linked services (connectors) Linked services contain configuration settings required for ADF to connect various external resources outside ADF. This information can include a server name, database name, credentials, and the like. This is similar to the connection string used to connect to the SQL Server database. Depending on an external resource, it can represent data stores—such as SQL Server, Oracle, and so on—or compute resources such as HDInsight to perform the execution of an activity. For example, an Azure Storage–linked service represents a connection string to connect to the Azure Storage account.
Dataset This component represents structures of data within data stores and provides more granular information about the data from linked sources you will use. For example, an Azure Storage–linked service represents a connection string to connect to the Azure Storage account, and the Azure Blob dataset represents the blob container, the folder and path, and the blob’s file name.
Activities This component represents the action taken on the data. A pipeline can contain one or more activities. Azure Data Factory currently provides three types of activities: data-movement activities, control activities, and data transformation activities.
Pipeline A pipeline is a logical grouping of activities that perform a task together.
Triggers This component is a unit of processing that decides when to commence a pipeline execution. Azure Data Factory supports the following three types of triggers:
Schedule trigger This invokes a pipeline on a scheduled time.
Tumbling window trigger This invokes a pipeline at an aperiodic interval, while retaining its state.
Event-based trigger This invokes a pipeline to respond to an event.
Integration runtime (IR) This component is a compute infrastructure used by ADF to carry out integration activities such as data movement, data flow, activity dispatch, and SSIS package execution. There are three types of integration runtimes:
Azure IR This is a fully managed, serverless compute used to perform data flow, data movement, and activity dispatch on a public and private network.
Self-hosted IR You can install a self-hosted IR inside on-premises networks secured by the Azure Storage Firewall or inside a virtual network. It makes only out-bound HTTPS calls to the internet. Currently, it is supported only on Windows.
Azure-SSIS IR This is used to natively execute SSIS packages.
Figure 2-4 shows how Azure Data Factory works.
){kind=link}
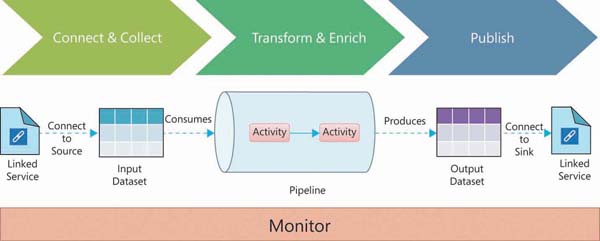
FIGURE 2-4 Azure Data Factory
The pipeline in Azure Data Factory is executed based on a schedule (for example, hourly, daily, or weekly) or is triggered by an external event. In the execution, the pipeline performs the following steps (refer to Figure 2-4):
Connect and collect Connect to the source system and collect the required data, as mentioned in the source-linked service and input dataset. You can connect to various source systems in Azure, on-premises, and in SaaS services. These systems can be used as a source, sink, or both, depending on the type of activity.
Transform and enrich After data is collected, it is transformed and enriched using the data flow activity that is executed on Spark internally without any knowledge of the Spark cluster and its programming. If you would like to code the transformation, you can use external activities for the execution of transformation on compute services such as Data Lake Analytics, HDInsight, Spark, and machine learning.
Publish After data is transformed or enriched, it can be published to target systems such as Azure SQL Database, Azure Cosmos DB, and so on.
Azure Data Factory provides the Monitor & Manage tile on the Data Factory blade, where you can monitor pipeline runs. You can also monitor the pipeline programmatically using SDK (.NET and Python), REST API, and PowerShell. The Azure Monitor and Health panels in the Azure Portal are additional ways to monitor the pipeline. You can view active pipeline executions as well as the executions history.
Azure Data Factory is useful when you need to ingest data from a multicloud and on-premises environment. ADF is a highly scalable service to handle gigabytes and petabytes of data.
Recommend a solution for data analysis
Once data is available in a data store, the next step is data analysis. Microsoft Azure offers following services for data analysis:
Azure Databricks
Azure Data Lake
Azure Databricks
Azure Databricks is a fully managed, fast, and easy analytics platform that is based on Apache Spark on Azure. It provides flexibility for one-click setup and offers streamlined workflows and shared collaborative and interactive workspaces. These workspaces enable data science teams consisting of data engineers, data scientists, and business analysts to collaborate and build data products.
Azure Databricks is natively integrated with Azure services such as Blob Storage, Azure Data Lake Storage, Cosmos DB, Azure Synapse Analytics, and the like. It supports popular BI tools, such as Alteryx, Looker, Power BI, Tableau, and so on, to connect Azure Databricks clusters to query data.
Azure Databricks supports the following sources, either directly in the Databricks runtime or by using small shell commands to enable access:
Avro files
Binary files
CSV files
Hive tables
Image files
JSON files
LZO compressed files
MLflow experiment files
Parquet files
Zip files
XML files
Let’s look at key components of Azure Databricks:
Databricks workspace The workspace is an environment for accessing all Azure Databricks assets. A workspace folder contains:
Notebook A web-based user interface to document runnable code, narrative text, and visualizations.
Dashboard A user interface that provides organized access to visualizations.
Library A collection of code available to the notebook or to jobs running on a cluster. Databricks provides many ready-made libraries, and you can add your own.
Experiment A collection of MLflow runs for training a machine learning model.
Data management The following objects hold data and are used to perform analytics as well as feed into the machine learning algorithm:
Databricks File System (DBFS) This is a file system abstraction layer over a blob store.
Database This is a systematic collection of information that can be easily accessed, managed, and updated.
Table This is structured data that can be queried using Apache Spark SQL and Apache Spark APIs.
Metastore This stores structured information from various tables and partitions.
Compute management Following are the components that you must know to run a computation in Azure Databricks:
Cluster This is a computing resource to run notebooks and jobs. There are two types of clusters: all-purpose clusters and job clusters. An all-purpose cluster is created manually using UI, REST API, or CLI. A job cluster is created by Databricks when you trigger a job.
Pool This is a collection of ready-to-use idle instances that reduce cluster start and autoscaling times.
Databricks runtime This is a set of core components that run on the cluster.
Job This is an execution of a notebook or JAR at a scheduled time or on demand.
You can easily integrate and read data from Azure services such as Azure Blob Storage, Azure Data Lake Storage, Azure Synapse Analytics (formerly Azure SQL Data Warehouse), and so on. You can also connect to Kafka, Event Hub, or IoT Hub and stream millions of events per second to Azure Databricks. You can integrate with Azure Key Vault to store and manage secrets such as keys, tokens, and passwords. Azure Databricks integrates closely with Power BI for interactive visualization. You can create Build and Release pipeline for Azure Databricks with Azure DevOps for continuous integration (CI) and continuous deployment (CD).
The Azure Databricks runtime is a set of components that run on the Databricks cluster. Azure Databricks offers several runtime variants, such as runtime for ML, runtime for Genomics, and the like. These versions are updated and released regularly to improve the usability, performance, and security of big data analytics. It also offers a serverless option that helps data scientists iterate quickly.
Azure Databricks easily integrates with Azure Active Directory and provides role-based access control (RBAC) and fine-grained user permissions for notebooks, jobs, clusters, and data.
Azure Data Lake
Azure Data Lake is a fully managed, highly scalable data lake service on the Azure cloud platform. It provides an enormous amount of storage to store structured, semi-structured, and unstructured data and perform analytics to gain business insights quickly. Figure 2-5 shows that the Azure Data Lake platform primarily consists of Azure Data Lake Analytics, Azure Data Lake Store, and Azure HDInsight.
){kind=link}
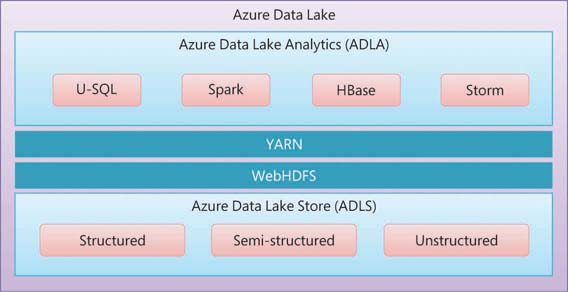
FIGURE 2-5 Azure Data Lake
Azure Data Lake includes three services:
Azure Data Lake Storage
Azure Data Lake Analytics
Azure HDInsight
Azure Data Lake Storage (ADLS)
Azure Data Lake Storage (ADLS) is a fully managed, hyper-scale, redundant, and cost-effective data repository solution for big data analytics. This repository provides storage with no limits or restrictions on the file size or the type of data stored (structured, semi-structured, unstructured, or total data volumes). You can store trillions of files, and one file can be petabytes in size if needed. This allows you to run massively parallel analytics.
ADLS easily integrates with Azure services such as Azure Databricks and Azure Data Factory. To protect data, it uses Azure Active Directory for authentication and RBAC, and it uses Azure Storage Firewall to restrict access and encryption of data at rest.
ADLS comes in two variants:
ADLS Generation 1 ADLS Gen 1 uses a Hadoop file system that is compatible with Hadoop Distributed File System (HDFS). It also exposes a WebHDFS-compatible REST API that can be easily used by an existing HDInsight service. ADLS Gen 1 is accessible using the new AzureDataLakeFilesystem (adl://) file system. This file system provides performance optimization that is currently not available in WebHDFS. ADLS Gen 1 can be easily integrated with Azure services such as Azure Data Factory, Azure HDInsight, Azure Stream Analytics, Power BI, Azure Event Hubs, and the like.
ADLS Generation 2 ADLS Gen 2 is built on Azure Blob Storage. Azure Storage brings its power, such as geo-redundancy; hot, cold, and archive tiers; additional metadata; and regional availability. ADLS Gen 2 combines all the features of Gen 1 with the power of Azure Storage, which greatly enriches performance, management, and security. Gen 2 uses a hierarchical namespace (HNS) to Azure Blob Storage, which allows the collection of objects within an account to be arranged into a hierarchy of directories and subdirectories, like a file system on a desktop computer.
Azure Data Lake Analytics (ADLA)
Azure Data Lake Analytics (ADLA) is a fully managed and on-demand data analytics service for the Azure cloud platform. It is a real-time analytic service built on Apache’s Hadoop Yet Another Resource Negotiator (YARN). It allows the parallel processing of very large volumes of data (structured, semi-structured, and unstructured), which eliminates the need to provision the underlying infrastructure. ADLA easily integrates with ADLS and Azure Storage Blobs, Azure SQL Database, and Azure Synapse Analytics (formerly SQL Data Warehouse).
In ADLA, you can perform data transformation and processing tasks using a program developed in U-SQL, R, Python, and .NET. U-SQL is a new query langugae that blends SQL and C# to process both structured and unstructured data of any size. You can also use Visual Studio as your integrated development environment (IDE) to develop a U-SQL script.
Performing analytics is quite easy with ADLA. As a developer, you simply write a script using U-SQL or your language of choice and submit it as a job.
ADLA pricing is based on Azure Data Lake Analytics Units (ADLAUs), also known as analytics units (AUs). AU is a unit of compute resource (CPU cores and memory) provided to run your job. Currently, an AU is the equivalent of two cores and 6 GB of RAM. A job is executed in four phases: preparation, queuing, execution, and finalization. You must pay for the duration of the job’s execution and finalization phase.
Azure Hdinsight
Azure Data Lake brings integration with the existing Azure HDInsight service. It is a fully managed, open-source Hadoop-based analytics service on the Azure cloud platform. Azure HDInsight uses the Hortonworks Data Platform (HDP) Hadoop distribution. It is designed to process a massive amount of streaming and historical data. It enables you to build big data applications using open-source frameworks such as Apache Hadoop, Apache Spark, Apache Hive, Apache Kafka, and Apache Storm. You can also easily integrate Azure HDInsight with a range of Azure services, such as Azure Cosmos DB, Azure Data Factory, Azure Blob Storage, Azure Event Hubs, and so on.
Azure Synapse Analytics
Azure Synapse Analytics is an evolution of Azure SQL Data Warehouse that brings the SQL data warehouse and big data analytics into a single service. It provides a unified experience to ingest, prepare, manage, and serve data for business intelligence and machine-learning needs.
Azure Synapse Analytics provides end-to-end analytic solutions that combine the power of a data warehouse, Azure Data Lake, and machine learning at an immense scale on the Azure cloud platform.
AZURE SYNAPSE STUDIO As shown in Figure 2-6, Azure Synapse Analytics includes a component called Azure Synapse Studio. This is a web-based interface that provides an end-to-end development experience. Using Azure Synapse Studio, you can interact with various services of Azure Synapse.
){kind=link}
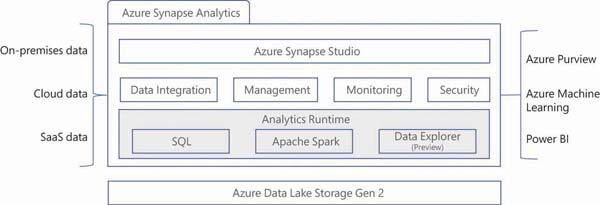
FIGURE 2-6 Azure Synapse Analytics
AZURE SYNAPSE SQL Azure Synapse Analytics also supports the use of Azure Synapse SQL. Azure Synapse SQL uses a node-based architecture that separates compute and storage. This separation enables you to scale compute independently of the data. You can pause the service to free up compute resources. You will be charged only for storage when you pause the service. The data remains intact in storage during this pause period.
Azure Synapse Consumption Models
Azure Synapse Analytics provides two consumption models:
Dedicated SQL pool Dedicated SQL pool (formerly SQL Data Warehouse) is a collection of provisioned analytic resources. You can scale up, scale down, or pause dedicated SQL pools during non-operational hours. The size of the dedicated pool is measured in Data Warehousing Units (DWUs). In dedicated SQL pools, queries are distributed in parallel across computer nodes using a massively parallel processing (MPP) engine. Figure 2-7 illustrates the Azure Synapse dedicated SQL pool architecture.
){kind=link}

FIGURE 2-7 Azure Synapse dedicated SQL pool
Serverless SQL pool As the name implies, with serverless SQL pools, you need not provision any infrastructure. It is scaled automatically to meet the query resource requirement. Once you provision an Azure Synapse workspace, you get a default serverless SQL pool endpoint. You can start querying data using the serverless SQL pool and will be charged based on the data process by each query run. Figure 2-8 illustrates the Azure Synapse serverless SQL pool architecture.
){kind=link}
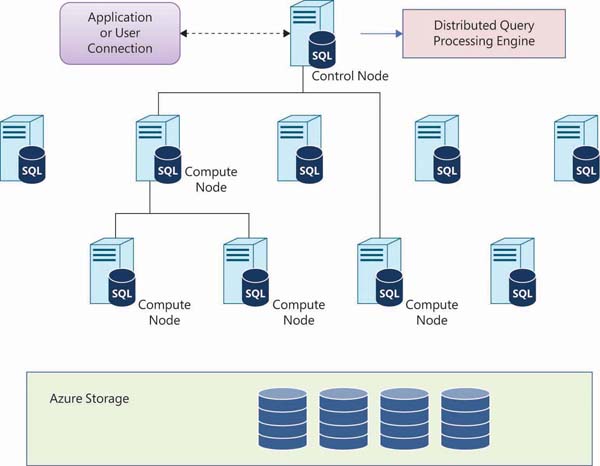
FIGURE 2-8 Azure Synapse serverless SQL pool
As shown in Figure 2-8, an Azure Synapse serverless SQL pool consists of the following components:
Control nodes A user or an application connects to control nodes and gives T-SQL commands to the control node for execution. A control node optimizes queries using the MPP engine and then distributes it to multiple compute nodes to run in parallel.
Compute nodes The Azure Synapse serverless SQL pool distributes processing across multiple compute nodes. It can use a maximum of 60 compute nodes for processing, which is determined by the service level for Azure Synapse SQL. (Again, DWU is the unit of compute power.) All the compute nodes run queries in parallel. The data movement service (DMS) manages data movement across compute nodes to run queries in parallel.
Azure Storage The Azure Synapse serverless SQL pool uses Azure Storage to store data. Data is horizontally partitioned and stored in a shard to optimize the performance of the system. In this sharding process, data is split across 60 distributions. There are three methods of distribution, which determine how rows in the table are split across nodes:
Round robin This is the default method of distribution. In this method, data is distributed evenly across the nodes. It is quick and straightforward to create, but it is not optimized for query performance.
Replicated In this method, a complete table is replicated across nodes. This method is suitable for small tables and provides faster query performance.
Hash In this method, a hash function is used to distribute data. One of the columns in the table is used as a distribution key column. Azure Synapse SQL automatically spreads the rows across all 60 distributions based on distribution key column value.
APACHE SPARK POOL Azure Synapse Analytics also provides a serverless Apache Spark pool, which is a fully managed Microsoft implementation of Apache Spark. An Apache Spark pool uses the Apache Spark core engine, which is a distributed execution engine. An Apache Spark cluster is managed by the YARN, yet another resource negotiator. YARN ensures proper use of the distributed engine to process the Spark queries and jobs.
Apache Spark pools support in-memory cluster computing, which is much faster than disk-based data processing. An Apache Spark pool is compatible with ADLS Gen 2 and Azure Storage, which helps it to process data stored in Azure. Apache Spark pools have multilanguage support for languages like Scala, C#, Spark SQL, Pyspark, Java, and so on.
DATA INTEGRATION Azure Synapse Analytics provides the same data integration engine that is available in Azure Data Factory. Thus, the experience of creating data pipelines is the same as that of Azure Data Factory. This allows for rich data transformation capabilities within Azure Synapse Analytics itself.
Security
Azure Synapse Analytics provides an array of security features:
Data encryption for data in transit and data at rest
Support for Azure AD and multifactor authentication
Object-level, row-level, and column-level security
Dynamic data masking
Support for network-level security with virtual networks and Azure Firewall