Introducing DAX
- By Alberto Ferrari and Marco Russo
- 7/20/2019
Introducing aggregators and iterators
Almost every data model needs to operate on aggregated data. DAX offers a set of functions that aggregate the values of a column in a table and return a single value. We call this group of functions aggregation functions. For example, the following measure calculates the sum of all the numbers in the SalesAmount column of the Sales table:
Sales := SUM ( Sales[SalesAmount] )
SUM aggregates all the rows of the table if it is used in a calculated column. Whenever it is used in a measure, it considers only the rows that are being filtered by slicers, rows, columns, and filter conditions in the report.
There are many aggregation functions (SUM, AVERAGE, MIN, MAX, and STDEV), and their behavior changes only in the way they aggregate values: SUM adds values, whereas MIN returns the minimum value. Nearly all these functions operate only on numeric values or on dates. Only MIN and MAX can operate on text values also. Moreover, DAX never considers empty cells when it performs the aggregation, and this behavior is different from their counterpart in Excel (more on this later in this chapter).
 NOTE
NOTE
MIN and MAX offer another behavior: if used with two parameters, they return the minimum or maximum of the two parameters. Thus, MIN (1, 2) returns 1 and MAX (1, 2) returns 2. This functionality is useful when one needs to compute the minimum or maximum of complex expressions because it saves having to write the same expression multiple times in IF statements.
All the aggregation functions we have described so far work on columns. Therefore, they aggregate values from a single column only. Some aggregation functions can aggregate an expression instead of a single column. Because of the way they work, they are known as iterators. This set of functions is useful, especially when you need to make calculations using columns of different related tables, or when you need to reduce the number of calculated columns.
Iterators always accept at least two parameters: the first is a table that they scan; the second is typically an expression that is evaluated for each row of the table. After they have completed scanning the table and evaluating the expression row by row, iterators aggregate the partial results according to their semantics.
For example, if we compute the number of days needed to deliver an order in a calculated column called DaysToDeliver and build a report on top of that, we obtain the report shown in Figure 2-6. Note that the grand total shows the sum of all the days, which is not useful for this metric:
){kind=link}
Sales[DaysToDeliver] = INT ( Sales[Delivery Date] - Sales[Order Date] )
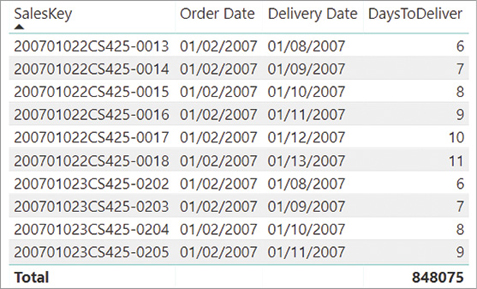
Figure 2-6 The grand total is shown as a sum, when you might want an average instead.
A grand total that we can actually use requires a measure called AvgDelivery showing the delivery time for each order and the average of all the durations at the grand total level:
AvgDelivery := AVERAGE ( Sales[DaysToDeliver] )
The result of this new measure is visible in the report shown in Figure 2-7.
){kind=link}
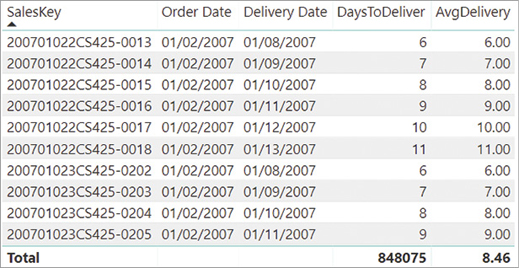
Figure 2-7 The measure aggregating by average shows the average delivery days at the grand total level.
The measure computes the average value by averaging a calculated column. One could remove the calculated column, thus saving space in the model, by leveraging an iterator. Indeed, although it is true that AVERAGE cannot average an expression, its counterpart AVERAGEX can iterate the Sales table and compute the delivery days row by row, averaging the results at the end. This code accomplishes the same result as the previous definition:
AvgDelivery :=
AVERAGEX (
Sales,
INT ( Sales[Delivery Date] - Sales[Order Date] )
)
The biggest advantage of this last expression is that it does not rely on the presence of a calculated column. Thus, we can build the entire report without creating expensive calculated columns.
Most iterators have the same name as their noniterative counterpart. For example, SUM has a corresponding SUMX, and MIN has a corresponding MINX. Nevertheless, keep in mind that some iterators do not correspond to any aggregator. Later in this book, you will learn about FILTER, ADDCOLUMNS, GENERATE, and other functions that are iterators even if they do not aggregate their results.
When you first learn DAX, you might think that iterators are inherently slow. The concept of performing calculations row by row looks like a CPU-intensive operation. Actually, iterators are fast, and no performance penalty is caused by using iterators instead of standard aggregators. Aggregators are just a syntax-sugared version of iterators.
Indeed, the basic aggregation functions are a shortened version of the corresponding X-suffixed function. For example, consider the following expression:
SUM ( Sales[Quantity] )
It is internally translated into this corresponding version of the same code:
SUMX ( Sales, Sales[Quantity] )
The only advantage in using SUM is a shorter syntax. However, there are no differences in performance between SUM and SUMX aggregating a single column. They are in all respects the same function.
We will cover more details about this behavior in Chapter 4. There we introduce the concept of evaluation contexts to describe properly how iterators work.