T-SQL Querying: TOP and OFFSET-FETCH
- By Itzik Ben-Gan, Kevin Farlee, Adam Machanic, Dejan Sarka
- 3/11/2015
- The TOP and OFFSET-FETCH filters
- Optimization of filters demonstrated through paging
- Using the TOP option with modifications
- Top N per group
- Median
- Conclusion
Optimization of filters demonstrated through paging
So far, I described the logical design aspects of the TOP and OFFSET-FETCH filters. In this section, I’m going to cover optimization aspects. I’ll do so by looking at different paging solutions. I’ll describe two paging solutions using the TOP filter, a solution using the OFFSET-FETCH filter, and a solution using the ROW_NUMBER function.
In all cases, regardless of which filtering option you use for your paging solution, an index on the ordering elements is crucial for good performance. Often you will get good performance even when the index is not a covering one. Curiously, sometimes you will get better performance when the index isn’t covering. I’ll provide the details in the specific implementations.
I’ll use the Orders table from the PerformanceV3 database in my examples. Suppose you need to implement a paging solution returning one page of orders at a time, based on orderid as the sort key. The table has a nonclustered index called PK_Orders defined with orderid as the key. This index is not a covering one with respect to the paging queries I will demonstrate.
Optimization of TOP
There are a couple of strategies you can use to implement paging solutions with TOP. One is an anchor-based strategy, and the other is TOP over TOP (nested TOP queries).
The anchor-based strategy allows the user to visit adjacent pages progressively. You define a stored procedure that when given the sort key of the last row from the previous page, returns the next page. Here’s an implementation of such a procedure:
USE PerformanceV3; IF OBJECT_ID(N'dbo.GetPage', N'P') IS NOT NULL DROP PROC dbo.GetPage; GO CREATE PROC dbo.GetPage @orderid AS INT = 0, -- anchor sort key @pagesize AS BIGINT = 25 AS SELECT TOP (@pagesize) orderid, orderdate, custid, empid FROM dbo.Orders WHERE orderid > @orderid ORDER BY orderid; GO
Here I’m assuming that only positive order IDs are supported. Of course, you can implement such an integrity rule with a CHECK constraint. The query uses the WHERE clause to filter only orders with order IDs that are greater than the input anchor sort key. From the remaining rows, using TOP, the query filters the first @pagesize rows based on orderid ordering.
Use the following code to request the first page of orders:
EXEC dbo.GetPage @pagesize = 25;
I got the following result (but yours may vary because of the randomization aspects used in the creation of the sample data):
orderid orderdate custid empid ----------- ---------- ----------- ----------- 1 2011-01-01 C0000005758 205 2 2011-01-01 C0000015925 251 ... 24 2011-01-01 C0000003541 316 25 2011-01-01 C0000005636 256
In this example, the last sort key in the first page is 25. Therefore, to request the second page of orders, you pass 25 as the input anchor sort key, like so:
EXEC dbo.GetPage @orderid = 25, @pagesize = 25;
Of course, in practice the last sort key in the first page could be different than 25, but in my sample data the keys start with 1 and are sequential. I got the following result when running this code:
orderid orderdate custid empid ----------- ---------- ----------- ----------- 26 2011-01-01 C0000017397 332 27 2011-01-01 C0000012629 27 28 2011-01-01 C0000016429 53 ... 49 2011-01-01 C0000015415 95 50 2010-12-06 C0000008667 117
To ask for the third page of orders, you pass 50 as the input sort key in the next page request:
EXEC dbo.GetPage @orderid = 50, @pagesize = 25;
I got the following output for the execution of this code:
orderid orderdate custid empid ----------- ---------- ----------- ----------- 51 2011-01-01 C0000000797 438 52 2011-01-01 C0000015945 47 53 2011-01-01 C0000013558 364 ... 74 2011-01-01 C0000019720 249 75 2011-01-01 C0000000807 160
The execution plan for the query is shown in Figure 5-1. I’ll assume the inputs represent the last procedure call with the request for the third page.
)
FIGURE 5-1 Plan for TOP with a single anchor sort key.
I’ll describe the execution of this plan based on data flow order (right to left). But keep in mind that the API call order is actually left to right, starting with the root node (SELECT). I’ll explain why that’s important to remember shortly.
The Index Seek operator performs a seek in the index PK_Orders to the first leaf row that satisfies the Start property of the Seek Predicates property: orderid > @orderid. In the third execution of the procedure, @orderid is 50. Then the Index Seek operator continues with a range scan in the index leaf based on the seek predicate. Absent a Prefix property of the Seek Predicates property, the range scan normally continues until the tail of the index leaf. However, as mentioned, the internal API call order is done from left to right. The Top operator has a property called Top Expression, which is set in the plan to @pagesize (25, in our case). This property tells the Top operator how many rows to request from the Nested Loops operator to its right. In turn, the Nested Loops operator requests the specified number of rows (25, in our case) from the Index Seek operator to its right. For each row returned from the Index Seek Operator, Nested Loops executes the Key Lookup operator to collect the remaining elements from the respective data row. This means that the range scan doesn’t proceed beyond the 25th row, and this also means that the Key Lookup operator is executed 25 times.
Not only is the range scan in the Index Seek operator cut short because of TOP’s row goal (Top Expression property), the query optimizer needs to adjust the costs of the affected operators based on that row goal. This aspect of optimization is described in detail in an excellent article by Paul White: “Inside the Optimizer: Row Goals In Depth.” The article can be found here: http://sqlblog.com/blogs/paul_white/archive/2010/08/18/inside-the-optimiser-row-goals-in-depth.aspx.
The I/O costs involved in the execution of the query plan are made of the following:
- Seek to the leaf of index: 3 reads (the index has three levels)
- Range scan of 25 rows: 0–1 reads (hundreds of rows fit in a page)
- Nested Loops prefetch used to optimize lookups: 9 reads (measured by disabling prefetch with trace flag 8744)
- 25 key lookups: 75 reads
In total, 87 logical reads were reported for the processing of this query. That’s not too bad. Could things be better or worse? Yes on both counts. You could get better performance by creating a covering index. This way, you eliminate the costs of the prefetch and the lookups, resulting in only 3–4 logical reads in total. You could get much worse performance if you don’t have any good index with the sort column as the leading key—not even a noncovering index. This results in a plan that performs a full scan of the data, plus a sort. That’s a very expensive plan, especially considering that you pay for it for every page request by the user.
With a single sort key, the WHERE predicate identifying the start of the qualifying range is straightforward: orderid > @orderid. With multiple sort keys, it gets a bit trickier. For example, suppose that the sort vector is (orderdate, orderid), and you get the anchor sort keys @orderdate and @orderid as inputs to the GetPage procedure. Standard SQL has an elegant solution for this in the form of a feature called row constructor (aka vector expression). Had this feature been implemented in T-SQL, you could have phrased the WHERE predicate as follows: (orderdate, orderid) > (@orderdate, @orderid). This also allows good optimization by using a supporting index on the sort keys similar to the optimization of a single sort key. Sadly, T-SQL doesn’t support such a construct yet.
You have two options in terms of how to phrase the predicate. One of them (call it the first predicate form) is the following: orderdate >= @orderdate AND (orderdate > @orderdate OR orderid > @orderid). Another one (call it the second predicate form) looks like this: (orderdate = @orderdate AND orderid > @orderid) OR orderdate > @orderdate. Both are logically equivalent, but they do get handled differently by the query optimizer. In our case, there’s a covering index called idx_od_oid_i_cid_eid defined on the Orders table with the key list (orderdate, orderid) and the include list (custid, empid).
Here’s the implementation of the stored procedure with the first predicate form:
IF OBJECT_ID(N'dbo.GetPage', N'P') IS NOT NULL DROP PROC dbo.GetPage; GO CREATE PROC dbo.GetPage @orderdate AS DATE = '00010101', -- anchor sort key 1 (orderdate) @orderid AS INT = 0, -- anchor sort key 2 (orderid) @pagesize AS BIGINT = 25 AS SELECT TOP (@pagesize) orderid, orderdate, custid, empid FROM dbo.Orders WHERE orderdate >= @orderdate AND (orderdate > @orderdate OR orderid > @orderid) ORDER BY orderdate, orderid; GO
Run the following code to get the first page:
EXEC dbo.GetPage @pagesize = 25;
I got the following output from this execution:
orderid orderdate custid empid ----------- ---------- ----------- ----------- 310 2010-12-03 C0000014672 218 330 2010-12-03 C0000009594 10 90 2010-12-04 C0000012937 231 ... 300 2010-12-07 C0000019961 282 410 2010-12-07 C0000001585 342
Run the following code to get the second page:
EXEC dbo.GetPage @orderdate = '20101207', @orderid = 410, @pagesize = 25;
I got the following output from this execution:
orderid orderdate custid empid ----------- ---------- ----------- ----------- 1190 2010-12-07 C0000004678 465 1270 2010-12-07 C0000015067 376 1760 2010-12-07 C0000009532 104 ... 2470 2010-12-09 C0000008664 205 2830 2010-12-09 C0000010497 221
Run the following code to get the third page:
EXEC dbo.GetPage @orderdate = '20101209', @orderid = 2830, @pagesize = 25;
I got the following output from this execution:
orderid orderdate custid empid ----------- ---------- ----------- ----------- 3120 2010-12-09 C0000015659 381 3340 2010-12-09 C0000008708 272 3620 2010-12-09 C0000009367 312 ... 2730 2010-12-10 C0000015630 317 3490 2010-12-10 C0000002887 306
As for optimization, Figure 5-2 shows the plan I got for the implementation using the first predicate form.
){kind=link}
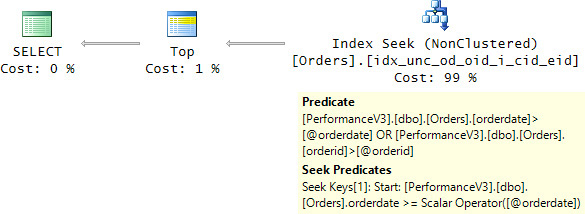
FIGURE 5-2 Plan for TOP with multiple anchor sort keys, first predicate form.
Observe that the Start property of the Seek Predicates property is based only on the predicate orderdate >= @orderdate. The residual predicate is orderdate > @orderdate OR orderid > @orderid. Such optimization could result in some unnecessary work scanning the pages holding the first part of the range with the first qualifying order date with the nonqualifying order IDs—in other words, the rows where orderdate = @orderdate AND orderid <= @orderid are going to be scanned even though they need not be returned. How many unnecessary page reads will be performed mainly depends on the density of the leading sort key—orderdate, in our case. The denser it is, the more unnecessary work is likely going to happen. In our case, the density of the orderdate column is very low (~1/1500); it is so low that the extra work is negligible. But, when the leading sort key is dense, you could get a noticeable improvement by using the second form of the predicate. Here’s an implementation of the stored procedure with the second predicate form:
IF OBJECT_ID(N'dbo.GetPage', N'P') IS NOT NULL DROP PROC dbo.GetPage; GO CREATE PROC dbo.GetPage @orderdate AS DATE = '00010101', -- anchor sort key 1 (orderdate) @orderid AS INT = 0, -- anchor sort key 2 (orderid) @pagesize AS BIGINT = 25 AS SELECT TOP (@pagesize) orderid, orderdate, custid, empid FROM dbo.Orders WHERE (orderdate = @orderdate AND orderid > @orderid) OR orderdate > @orderdate ORDER BY orderdate, orderid; GO
Run the following code to get the third page:
EXEC dbo.GetPage @orderdate = '20101209', @orderid = 2830, @pagesize = 25;
The query plan for the implementation with the second form of the predicate is shown in Figure 5-3.
){kind=link}
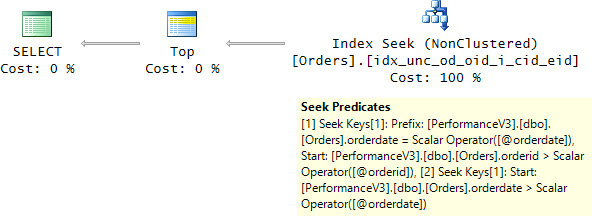
FIGURE 5-3 Plan for TOP with multiple anchor sort keys, second predicate form.
Observe that there’s no residual predicate, only Seek Predicates. Curiously, there are two seek predicates. Remember that, generally, the range scan performed by an Index Seek operator starts with the first match for Prefix and Start and ends with the last match for Prefix. In our case, one predicate (marked in the plan as [1] Seek Keys...) starts with orderdate = @orderdate AND orderid > @orderid and ends with orderdate = @orderdate. Another predicate (marked in the plan as [2] Seek Keys...) starts with orderdate = @orderdate and has no explicit end. What’s interesting is that during query execution, if Top Expression rows are found by the first seek, the execution of the operator short-circuits before getting to the second. But if the first seek isn’t sufficient, the second will be executed. The fact that in our example the leading sort key (orderdate) has low density could mislead you to think that the first predicate form is more efficient. If you test both implementations and compare the number of logical reads, you might see the first one performing 3 or more reads and the second one performing 6 or more reads (when two seeks are used). But if you test the solutions with a dense leading sort key, you will notice a significant difference in favor of the second solution.
There’s another method to using TOP to implement paging. You can think of it as the TOP over TOP, or nested TOP, method. You work with @pagenum and @pagesize as the inputs to the GetPage procedure. There’s no anchor concept here. You use one query with TOP to filter @pagenum * @pagesize rows based on the desired order. You define a table expression based on this query (call it D1). You use a second query against D1 with TOP to filter @pagesize rows, but in inverse order. You define a table expression based on the second query (call it D2). Finally, you write an outer query against D2 to order the rows in the desired order. Run the following code to implement the GetPage procedure based on this approach:
IF OBJECT_ID(N'dbo.GetPage', N'P') IS NOT NULL DROP PROC dbo.GetPage;
GO
CREATE PROC dbo.GetPage
@pagenum AS BIGINT = 1,
@pagesize AS BIGINT = 25
AS
SELECT orderid, orderdate, custid, empid
FROM ( SELECT TOP (@pagesize) *
FROM ( SELECT TOP (@pagenum * @pagesize) *
FROM dbo.Orders
ORDER BY orderid ) AS D1
ORDER BY orderid DESC ) AS D2
ORDER BY orderid;
GO
Here are three consecutive calls to the procedure requesting the first, second, and third pages:
EXEC dbo.GetPage @pagenum = 1, @pagesize = 25; EXEC dbo.GetPage @pagenum = 2, @pagesize = 25; EXEC dbo.GetPage @pagenum = 3, @pagesize = 25;
The plan for the third procedure call is shown in Figure 5-4.
)
FIGURE 5-4 Plan for TOP over TOP.
The plan is not very expensive, but there are three aspects to it that are not optimal when compared to the implementation based on the anchor concept. First, the plan scans the data in the index from the beginning of the leaf until the last qualifying row. This means that there’s repetition of work—namely, rescanning portions of the data. For the first page requested by the user, the plan will scan 1 * @pagesize rows, for the second page it will scan 2 * @pagesize rows, for the nth page it will scan n * @pagesize rows. Second, notice that the Key Lookup operator is executed 75 times even though only 25 of the lookups are relevant. Third, there are two Sort operators added to the plan: one reversing the original order to get to the last chunk of rows, and the other reversing it back to the original order to present it like this. For the third page request, the execution of this plan performed 241 logical reads. The greater the number of pages you have, the more work there is.
The benefit of this approach compared to the anchor-based strategy is that you don’t need to deal with collecting the anchor from the result of the last page request, and the user is not limited to navigating only between adjacent pages. For example, the user can start with page 1, request page 5, and so on.
Optimization of OFFSET-FETCH
The optimization of the OFFSET-FETCH filter is similar to that of TOP. Instead of reinventing the wheel by creating an entirely new plan operator, Microsoft decided to enhance the existing Top operator. Remember the Top operator has a property called Top Expression that indicates how many rows to request from the operator to the right and pass to the operator to the left. The enhanced Top operator used to process OFFSET-FETCH has a new property called OffsetExpression that indicates how many rows to request from the operator to the right and not pass to the operator to the left. The OffsetExpression property is processed before the Top Expression property, as you might have guessed.
To show you the optimization of the OFFSET-FETCH filter, I’ll use it in the implementation of the GetPage procedure:
IF OBJECT_ID(N'dbo.GetPage', N'P') IS NOT NULL DROP PROC dbo.GetPage; GO CREATE PROC dbo.GetPage @pagenum AS BIGINT = 1, @pagesize AS BIGINT = 25 AS SELECT orderid, orderdate, custid, empid FROM dbo.Orders ORDER BY orderid OFFSET (@pagenum - 1) * @pagesize ROWS FETCH NEXT @pagesize ROWS ONLY; GO
As you can see, OFFSET-FETCH allows a simple and flexible solution that uses the @pagenum and @pagesize inputs. Use the following code to request the first three pages:
EXEC dbo.GetPage @pagenum = 1, @pagesize = 25; EXEC dbo.GetPage @pagenum = 2, @pagesize = 25; EXEC dbo.GetPage @pagenum = 3, @pagesize = 25;
NOTE

Remember that under the default isolation level Read Committed, data changes between procedure calls can affect the results you get, causing you to get the same row in different pages or skip some rows. For example, suppose that at point in time T1, you request page 1. You get the rows that according to the paging sort order are positioned 1 through 25. Before you request the next page, at point in time T2, someone adds a new row with a sort key that makes it the 20th row. At point in time T3, you request page 2. You get the rows that, in T1, were positioned 25 through 49 and not 26 through 50. This behavior could be awkward. If you want the entire sequence of page requests to interact with the same state of the data, you need to submit all requests from the same transaction running under the snapshot isolation level.
The plan for the third execution of the procedure is shown in Figure 5-5.
)
FIGURE 5-5 Plan for OFFSET-FETCH.
As you can see in the plan, the Top operator first requests OffsetExpression rows (50, in our example) from the operator to the right and doesn’t pass those to the operator to the left. Then it requests Top Expression rows (25, in our example) from the operator to the right and passes those to the operator to the left. You can see two levels of inefficiency in this plan compared to the plan for the anchor solution. One is that the Index Scan operator ends up scanning 75 rows, but only the last 25 are relevant. This is unavoidable without an input anchor to start after. But the Key Lookup operator is executed 75 times even though, theoretically, the first 50 times could have been avoided. Such logic to avoid applying lookups for the first OffsetExpression rows wasn’t added to the optimizer. The number of logical reads required for the third page request is 241. The farther away the page number you request is, the more lookups the plan applies and the more expensive it is.
Arguably, in paging sessions users don’t get too far. If users don’t find what they are looking for after the first few pages, they usually give up and refine their search. In such cases, the extra work is probably negligible enough to not be a concern. However, the farther you get with the page number you’re after, the more the inefficiency increases. For example, run the following code to request page 1000:
EXEC dbo.GetPage @pagenum = 1000, @pagesize = 25;
This time, the plan involves 25,000 lookups, resulting in a total number of logical reads of 76,644. Unfortunately, because the optimizer doesn’t have logic to avoid the unnecessary lookups, you need to figure this out yourself if it’s important for you to eliminate unnecessary costs. Fortunately, there is a simple trick you can use to achieve this. Have the query with the OFFSET-FETCH filter return only the sort keys. Define a table expression based on this query (call it K, for keys). Then in the outer query, join K with the underlying table to return all the remaining attributes you need. Here’s the optimized implementation of GetPage based on this strategy:
ALTER PROC dbo.GetPage
@pagenum AS BIGINT = 1,
@pagesize AS BIGINT = 25
AS
WITH K AS
(
SELECT orderid
FROM dbo.Orders
ORDER BY orderid
OFFSET (@pagenum - 1) * @pagesize ROWS FETCH NEXT @pagesize ROWS ONLY
)
SELECT O.orderid, O.orderdate, O.custid, O.empid
FROM dbo.Orders AS O
INNER JOIN K
ON O.orderid = K.orderid
ORDER BY O.orderid;
GO
Run the following code to get the third page:
EXEC dbo.GetPage @pagenum = 3, @pagesize = 25;
You will get the plan shown in Figure 5-6.
)
FIGURE 5-6 Plan for OFFSET-FETCH, minimizing lookups.
As you can see, the Top operator is used early in the plan to filter the relevant 25 keys. Then only 25 executions of the Index Seek operator are required, plus 25 executions of the Key Lookup operator (because PK_Orders is not a covering index). The total number of logical reads required for the processing of this plan for the third page request was reduced to 153. This doesn’t seem like a dramatic improvement when compared to the 241 logical reads used in the previous implementation. But try running the procedure with a page that’s farther out, like 1000:
EXEC dbo.GetPage @pagenum = 1000, @pagesize = 25;
The optimized implementation uses only 223 logical reads compared to the 76,644 used in the previous implementation. That’s a big difference!
Curiously, a noncovering index created only on the sort keys, like PK_Orders in our case, can be more efficient for the optimized solution than a covering index. That’s because with shorter rows, more rows fit in a page. So, in cases where you need to skip a substantial number of rows, you get to do so by scanning fewer pages than you would with a covering index. With a noncovering index, you do have the extra cost of the lookups, but the optimized solution reduces the number of lookups to the minimum.
Optimization of ROW_NUMBER
Another common solution for paging is using the ROW_NUMBER function to compute row numbers based on the desired sort and then filtering the right range of row numbers based on the input @pagenum and @pagesize.
Here’s the implementation of the GetPage procedure based on this strategy:
IF OBJECT_ID(N'dbo.GetPage', N'P') IS NOT NULL DROP PROC dbo.GetPage;
GO
CREATE PROC dbo.GetPage
@pagenum AS BIGINT = 1,
@pagesize AS BIGINT = 25
AS
WITH C AS
(
SELECT orderid, orderdate, custid, empid,
ROW_NUMBER() OVER(ORDER BY orderid) AS rn
FROM dbo.Orders
)
SELECT orderid, orderdate, custid, empid
FROM C
WHERE rn BETWEEN (@pagenum - 1) * @pagesize + 1 AND @pagenum * @pagesize
ORDER BY rn; -- if order by orderid get sort in plan
GO
Run the following code to request the first three pages:
EXEC dbo.GetPage @pagenum = 1, @pagesize = 25; EXEC dbo.GetPage @pagenum = 2, @pagesize = 25; EXEC dbo.GetPage @pagenum = 3, @pagesize = 25;
The plan for the third page request is shown in Figure 5-7.
)
FIGURE 5-7 Plan for ROW_NUMBER.
Interestingly, the optimization of this solution is similar to that of the solution based on the OFFSET-FETCH filter. You will find the same inefficiencies, including the unnecessary lookups. As a result, the costs are virtually the same. For the third page request, the number of logical reads is 241. Run the procedure again asking for page 1000:
EXEC dbo.GetPage @pagenum = 1000, @pagesize = 25;
The number of logical reads is now 76,644. You can avoid the unnecessary lookups by applying the same optimization principle used in the improved OFFSET-FETCH solution, like so:
ALTER PROC dbo.GetPage
@pagenum AS BIGINT = 1,
@pagesize AS BIGINT = 25
AS
WITH C AS
(
SELECT orderid, ROW_NUMBER() OVER(ORDER BY orderid) AS rn
FROM dbo.Orders
),
K AS
(
SELECT orderid, rn
FROM C
WHERE rn BETWEEN (@pagenum - 1) * @pagesize + 1 AND @pagenum * @pagesize
)
SELECT O.orderid, O.orderdate, O.custid, O.empid
FROM dbo.Orders AS O
INNER JOIN K
ON O.orderid = K.orderid
ORDER BY K.rn;
GO
Run the procedure again requesting the third page:
EXEC dbo.GetPage @pagenum = 3, @pagesize = 25;
The plan for the optimized solution is shown in Figure 5-8.
)
FIGURE 5-8 Plan for ROW_NUMBER, minimizing lookups.
Observe that the Top operator filters the first 75 rows, and then the Filter operator filters the last 25, before applying the seeks and the lookups. As a result, the seeks and lookups are executed only 25 times. The execution of the plan for the third page request involves 153 logical reads, compared to 241 required by the previous solution.
Run the procedure again, this time requesting page 1000:
EXEC dbo.GetPage @pagenum = 1000, @pagesize = 25;
This execution requires only 223 logical reads, compared to 76,644 required by the previous solution.